
What Is Apache Spark?
Spark is a distributed data processing framework, which is used for a wide range of situations. Apache spark holds libraries for SQL, streaming, machine learning, and graph computation, that can be used collectively in an application. Spark supports programming languages like Java, Python, Scala, and R. Application developers broadly use Apache Spark framework for querying, analyzing, and transforming the data to scale rapidly. ETL and SQL kind tasks are those that are highly related to Spark to process massive datasets, machine learning, data streaming, and much more.
Sparkdatabox is one of the best apache spark training in Coimbatore They are alsooffer Oracle Database, Java, Apache Tomcat, SQL and other courses.
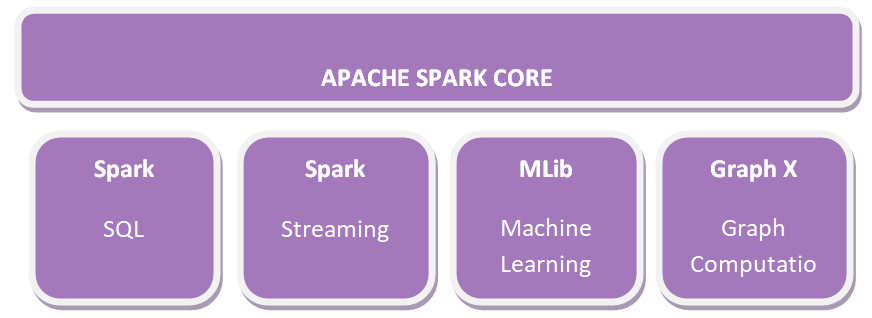
Apache Spark Core
Spare Core is the fundamental architecture of Spark that incorporates the segments for work scheduling, performing multiple memory processes, error tolerance, etc. Spark Core acts as a heart to the API that composed of RDD. Furthermore, Spark Core implements APIs for creating and managing data in RDD.
Spark SQL
Apache Spark operates on unorganized data applying its ‘Go to’ tool, Spark SQL. Spark SQL supports data querying through SQL and Apache Hive’s sort of SQL termed as Hive Query Language (HQL). Spark SQL also supports data from multiple origins such as parse tables, log files, JSON, etc. It enables programmers to connect SQL queries with programmable switches or manipulations carried by RDD in languages like Python, Java, Scala, and R.
Spark Streaming
Spark Streaming denotes live streams of data. Data produced by different roots are processed at the rapid speed by Spark Streaming. The data comprise log files, reports, including status updates by users, etc.
GraphX
GraphX is Apache Spark’s library for magnifying graphs and letting graph-parallel computation. Apache Spark incorporates several graph algorithms that assist users in parsing graph analytics.

MLlib
Apache Spark appears with a library comprising typical Machine Learning (ML) services called MLlib. It presents different types of ML algorithms like regression, clustering, and distribution, which can execute multiple operations on data to obtain significant insights from it.
What does spark implement?
Spark is very proficient in managing multiple data storage capacity of datasets at a point, grouped over a clump of interacting implicit servers. Spark includes a collective set of libraries and APIs and supports programming languages like Java, Python, R, and Scala. The versatility and adaptability make it the ideal tool for a wide range of real-time scenarios. Spark is usually processed with:
- Distributed data storage – MapR XD, Hadoop’s HDFS, and Amazon’s S3,
- Accessible NoSQL databases – Apache HBase, MapR Database, Cassandra, and MongoDB
- Distributed messaging repositories – MapR Event Store and Apache Kafka.
Features of Apache Spark
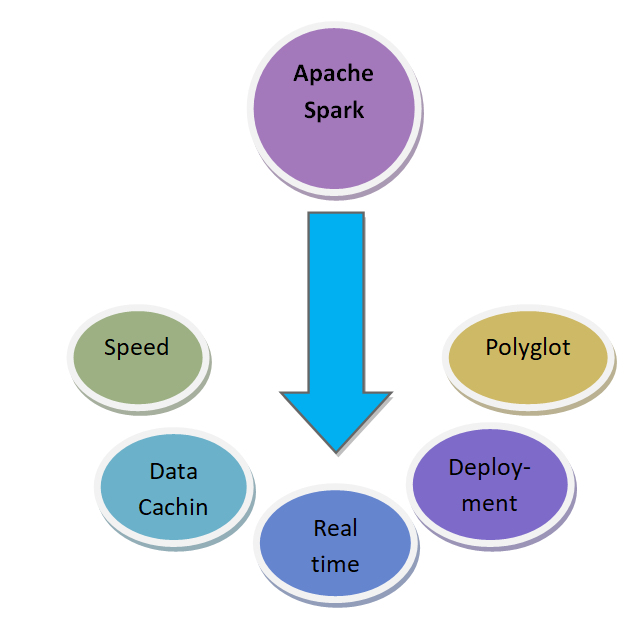
Speed: Spark is 100 xs quicker than other conventional data processing frameworks.
Great Caching: Spark presents robust data caching benefits and disk resolution capacities.
Real-Time Computation: Spark offers real-time computation and reduced latency because of its in-memory calculation.
Deployment: Spark can be deployed over Mesos, Hadoop through Yarn, or otherwise, by Spark’s own cluster handler.
Polyglot: Polyglot is a unique feature of spark framework as it can be coded using all four languages like Java, Python, Scala, and R.
Even though Spark was meant in Scala, thus presents it nearly ten times faster than Python, but the fact is that the Scala is faster only when the number of hubs used is more limited.
Real-life uses of Apache Spark
Numerous businesses are utilizing Apache Spark to develop their business market. These organizations collect massive data from users and utilize them to intensify customer assistance. Some of the companies using Apache Spark are as follows:
1. E-commerce: Various e-commerce monsters adopt Apache Spark to enhance their consumer services. The companies are as follows:
a. eBay
b. Alibaba
2. Healthcare
3. Media and Entertainment:
For instance, Netflix, one of the famous entertainer media for video streaming, uses Apache Spark to promote programs to their customers based on the former programs they have viewed.
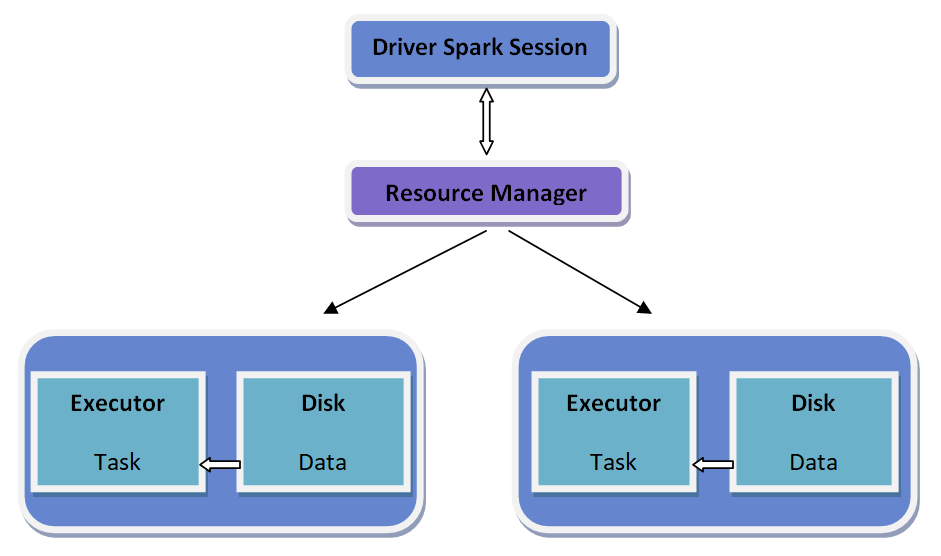
How does a Spark application work?
The below diagram displays the working of spark application:
- Spark application works independently, organized by the Spark Session object in the driver system.
- The source or cluster handler allocates tasks to operators based on task per partition.
- A task employs its piece of work to the dataset in its partition and results in a new partition dataset. As iterative algorithms involve processes frequently to data, they avail from caching datasets over redundancies.
- Outputs are transferred back to the driver; otherwise, it can be saved on to the disk.
The workflow of Spark
A much-demanded profession
Today, Apache Spark is one of the leading frameworks among the Big Data world all around the world. Apache Spark is beholding great demand with businesses noticing it more challenging to hire the best experts to carry on daring tasks in real-world plots.
And it is a fact that Apache Spark experts are paid the highest among the other Hadoop development tools.
Broad arrays of technology merchants are responsive to promote Spark, appreciating the opportunity to enlarge their current big data outcomes into regions where Spark produces the real advantage of querying and machine learning.