
Apache Hadoop training in Coimbatore YARN is a resource management and job computing system in the shared Hadoop processing paradigm. YARN is one of the core components of Hadoop and is liable for allotting resources to the multiple applications operating in a Hadoop cluster and arranging the jobs to be performed on varying cluster nodes.
The term YARN refers to – Yet Another Resource Negotiator. However, YARN is generally attributed to the acronym alone; the complete name was self-objecting banter on the frame of its developers. The technology developed into Apache Hadoop sub-framework within the Apache Software Foundation (ASF) in 2012 and was one of the principal traits appended in Hadoop 2.0, which was published for a trial that year and frequently became ready in October 2013.
The extension of YARN remarkably extended the prospective effectiveness of Hadoop. The first manifestation of Hadoop carefully assembled the Hadoop Distributed File System (HDFS) with the batch-tailored MapReduce programming framework and processing powerhouse. It also acted as the resource manager and task organizer of the big data platform. Therefore, Hadoop 1.0 systems can only operate MapReduce applications, which is a constraint that Hadoop YARN passed.

Before gaining its canonical name, YARN was unofficially called MapReduce 2/NextGen MapReduce. And YARN proposed a unique strategy that separate cluster resource management and scheduling from MapReduce data processing part, letting Hadoop hold up different types of processing and a more comprehensive collection of applications. For instance, Now Hadoop clusters can manage interactive querying, data streaming and real-life data statics applications on Apache Spark and other processing transformers together with MapReduce batch operations.
Sparkdatabox is one of the best Free online training course with certification They offer Oracle Database, Java, Apache Tomcat, SQL and other courses.
Essential components of Hadoop YARN
In MapReduce, a Job Tracker control process commanded resource management, scheduling, and supervising of processing operations. It composed of secondary processes called Task Trackers to manage individual map and reduce jobs and report back about their development, but most of the resource allotment and management activity is consolidated in Job Tracker. But it generated execution barrier and scalability obstacles as cluster volumes, and the number of requests and affiliated Task Trackers got increased.
Apache Hadoop YARN moved the control of process monitoring and execution by decentralizing it, i.e., it separated the multiple tasks into the following components like:
- Resource Manager: A global Resource Manager that receives job assignments from the client, organizes the jobs and designates resources to them
- Node Manager: A NodeManager slave – connected at every node – works as a monitoring and broadcasting factor of the Resource Manager
- Application Master: An ApplicationMaster – designed for every application – deal for resources and operate with the NodeManager to perform and control tasks
- Resource containers: NodeManagers manage resource containers and allotted the system resources designated to specific applications
The architecture of Hadoop yarn
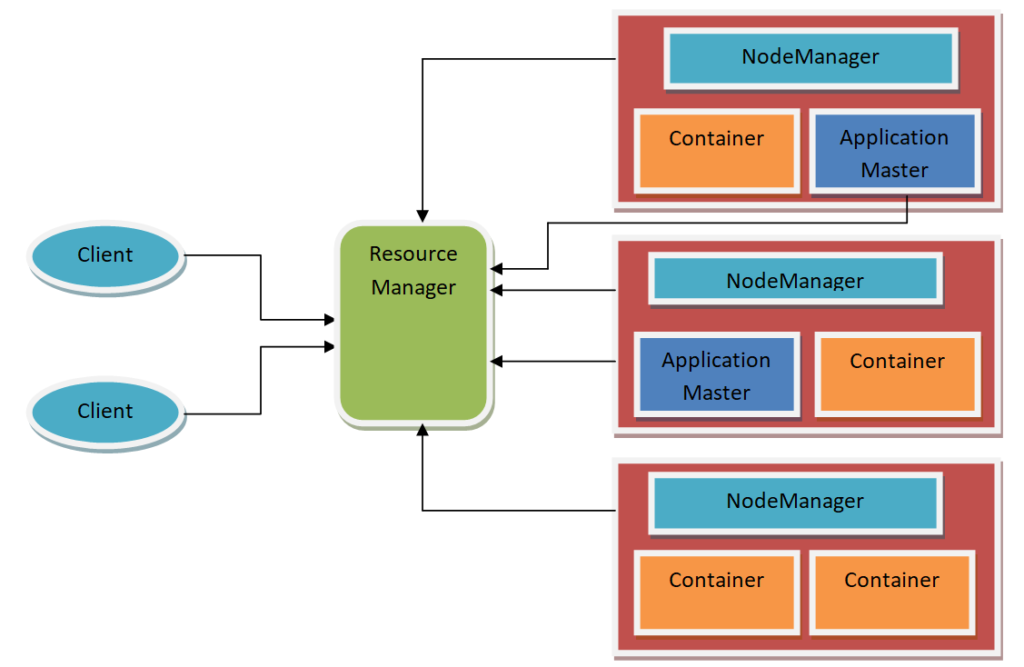
- The client assigns the processing jobs to the Resource Manager
- Resource Manager operates with ApplicationMasters and NodeManagers to organize execute and manage the jobs.
YARN containers are usually placed up in nodes and programmed to perform jobs, mainly when there are system resources ready for them. While Hadoop 3.0 scored support for building “opportunistic containers” that can be lined up at NodeManagers to expect for resources to be available. The opportunistic container intends to optimize the performance of cluster resources and, eventually, boost overall processing production in a Hadoop system.
Additionally, while the conventional strategy has been to operate YARN containers straight on cluster nodes, Hadoop 3.1 will incorporate the strength to seat them inside Docker containers. That would confine applications from each other and the NodeManager’s execution conditions; besides, varied versions of applications could be operated together in varying Docker containers.
Features and functions of Hadoop Yarn
In a cluster approach, YARN rests between HDFS and the processing powerhouses that are applied to drive applications. It connects a primary resource manager with containers, application administrators, and node-measure agents that control processing procedures in individual cluster nodes. YARN carefully allot resources to applications as required, a capacity intended to promote resource utilization and effective performance of the application, associated with the unvarying allocation strategy of MapReduce.
- Multiple Scheduling Methods – Yarn supports and works on a chain format to present the processing tasks.
- First-In, First-Out (FIFO) – The inbuilt FIFO format drives the applications on a first-in-first-out approach.
But, that is not favorable for clusters that are dealt with different users. Here is where Hadoop’s pluggable Fair Scheduler agent comes into the action. When the clusters are shared between multiple users, this tool allocates each job racing at the corresponding point the “fair share,” the concept of that supports resource cluster on a prioritized format that the scheduler computes.
- Capacity Scheduler – The tool that facilitates Hadoop clusters to operate as multi-tenant systems shared by multiple systems in a single Organization or by various organizations, where each one of them gaining a secured processing potential based on different service-level agreements. It applies hierarchical queues and sub-queues to assure that adequate cluster resources are allotted to each application of the users before assigning jobs in other queues hit into unutilized resources.
- Reservation System – It allows users to hold back cluster resources in advance for required processing jobs to make sure they run without any issues. In order to prevent overburdening a cluster with these reservations, IT professionals have the option to restrict the number of resources that can be reserved by single users and fix automatic procedures to refuse reservation applications that beat the limitation.
- YARN Federation – It is one of the remarkable features of Hadoop YARN that was introduced in Hadoop 3.0, which regularly found available in December 2017. The federation capacity is intended to boost the number of nodes that an individual YARN implementation can bear from 10,000 to massive amounts by utilizing a routing layer to combine multiple “subclusters,” each outfitted with its specific resource manager. The conditions will operate as a single enormous cluster that can stream processing jobs on any accessible nodes.
Advantages of YARN
Utilizing Apache Hadoop YARN to depart HDFS from MapReduce caused the Hadoop system more appropriate for real-time operation values and other applications that could not rest for group jobs to complete. Currently, MapReduce is merely one of the several processing powerhouses that can manage Hadoop applications. And it does not contain a secured on batch processing in Hadoop. In numerous circumstances, users are supplanting it with Spark to perceive more convincing performance on batch processing, like abstraction, modifying, and loading tasks.
Spark can also control stream processing requests in Hadoop clusters. This is because of YARN, application including Apache Flink and Apache Storm. YARN has additionally initiated up new techniques for Apache HBase, a partner database to HDFS, Apache Hive, Apache Impala, Apache Drill, Presto and other SQL-on-Hadoop query locomotives. Extending it to broader application and technology options, YARN grants scalability, effective use of resources, excellent availability, and improved performance than MapReduce.
Hi to all, how is the whole thing, I think every one is
getting more from this web site, and your views are nice
designed for new users.