
we are providing Big Data Hadoop course in Coimbatore The term ‘Big Data’ is a name used to denote the sets of massive data, which cover large size, great rapidity, and a diversity of data that is rising time by time. The old data management system is quite challenging to process big data. And hence, the Apache Software Foundation launched a new framework ‘Hadoop’ to unlock the Big data management difficulties.
Hadoop
Hadoop framework is an open-source structure that saves and processes Big data in a grouped ecosystem. Hadoop holds two different modules, like:
- MapReduce: A similar programming pattern for processing massive volumes of standardized, semi-organized, and unorganized data on vast clumps of a specialty tool.
- HDFS: Hadoop Distributed File System is a member of the Hadoop framework, utilized to store and process a large amount of data. It affords a fault-tolerant file system to run on commodity hardware.
The Hadoop framework includes distinct sub-tools, which are employed to help Hadoop modules. The sub tools are as follows:
- Sqoop: It is utilized to send and receive among HDFS and RDBMS.
- Pig: It is an official language platform used to promote a script for MapReduce operations.
- Hive: It is a platform used to generate SQL typescripts to perform MapReduce operations.

WHAT IS HIVE?
Apache Hive is a data warehouse system developed on the summit of Apache Hadoop that promotes easy data encapsulation, ad-hoc queries, and analysis of large datasets collected in a distributed computer ecosystem integrated with Hadoop, which also includes the MapR Data Platform with MapR XD and MapR Database.
Sparkdatabox is one of the best Free online training course with certification They offer Oracle Database, Java, Apache Tomcat, SQL and other courses.
The important Features of Hive
- Tables and databases are created prior to loading the data into those tables.
- Hive is a data warehouse that is created for handling and querying only the standardized data, which is stored in tables.
- The SQL language of Hive segregates the user from a complicated Map Reduce program. Instead, it reuses well-known concepts of relational database system like rows, columns, tables, schema, and so on, for the comfort of knowledge and learning.
- Map Reduce does not hold query optimization and usability characteristics like UDFs to deal with the structured data while the Hive framework includes an effective query optimization and execution.
- Hive can utilize directory structures to “partition” data to enhance the performance of specific queries as the Hadoop framework operates on flat files.
- Hive implements a command-line interface (CLI) to write Hive queries utilizing Hive Query Language (HQL)
- Hive supports four different file forms such as TEXTFILE, SEQUENCE FILE, ORC, and RCFILE.
- Hive uses two different types of the database for storage:
- Derby database – for single-user metadata storage
- MYSQL – for multiple user metadata or shared metadata
The Architecture of Hive
The flow diagram of Hive query:
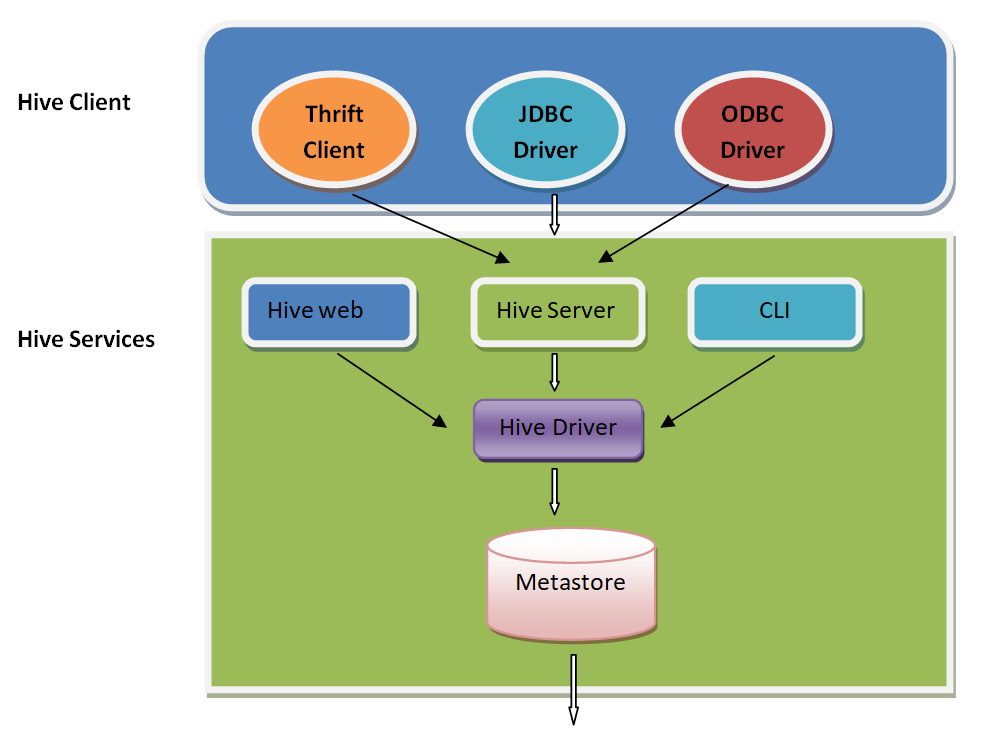
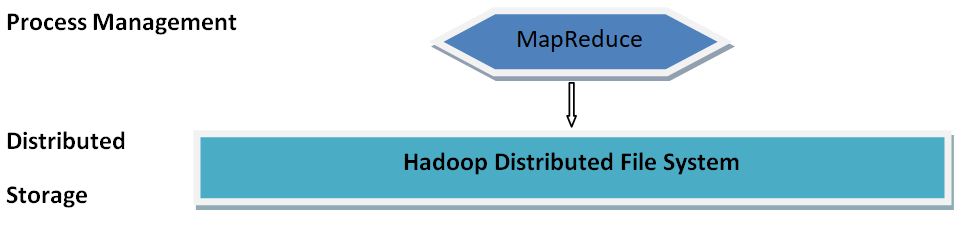
The primary components of the Hive:
Hive Clients: Hive supports applications written in different languages, which include C++, Java, and Python, etc. by using Thrift, JDBC, and ODBC drivers. Hence, it is simple to write Hive client applications in any of your favorite languages.
Hive Services: Hive caters different service support like web Interface, CLI, etc. to work on queries.
Process Management: Hive literally makes use of the Hadoop MapReduce framework to perform the queries.
Distributed Storage: As Hive is developed on the tip of Hadoop, it tends to use HDFS for the distributed storage.
Hive Clients
The Hive supports various sorts of client requests to perform queries. Those clients are classified into three types:
Thrift Clients: Hive server is Thrift based service provider platform, and so it serves the request from every language that supports Thrift.
JDBC Clients: Hive encourages the bond between Java applications and Hive by using a JDBC driver. JDBC driver is specified in the class apache.hadoop.hive.jdbc.HiveDriver.
ODBC Clients: ODBC Driver enables applications supporting ODBC protocol to correlate with Hive. For instance, the JDBC driver, ODBC utilizes Thrift to interface with the Hive server.
Hive Services
The services provided by Hive are as follows:
- Hive CLI: The Hive Command Line Interface (CLI) is a default shell present in, which aids in executing the Hive queries and commands.
- Hive Web User Interface: The Hive Web UI presents a web-based GUI in order to execute Hive queries and commands.
- Hive Server: It is developed on the Apache Thrift server, and hence it is called to be Thrift server. It facilitates different clients to submit requests to the Hive driver and gain the ultimate result.
- Hive Driver: Hive Driver is accountable to receive queries varied sources such as Thrift, CLI, JDBC, ODBC, Web UL interface through a Hive client.
Hive Compiler: The mission of the compiler is parsing the query, performing semantic analysis on multiple queries statements using the schema found in the metastore.
Optimizer: Makes the optimized relevant plan in the frame of a Directed Acyclic Graph (DAG) of MapReduce and HDFS roles.
Executor: Right after a perfect compilation and optimization process, the execution engine performs these tasks based on their dependencies with Hadoop.
Metastore: Metastore is the primary treasury of Hive metadata in the Hive Architecture. It collects the metadata for Hive tables (metadata in a sense – the schema and place) and partitions in a relational database. It grants access to the client on these data with the use of metastore service API. Hive metastore holds two key factors like:
- One of the factors providing access to metastore for other Hive services.
- The Disk storage – for the Hive metadata, which is isolated from HDFS storage
What are the advantages of learning Hive?
Apache Hive helps you operate with the Hadoop framework in a highly productive way. It is a comprehensive statistics repository foundation that is organized on the head of the Hadoop framework. Hive is specially used to deal with querying of data, robust data analysis, and data summarization while operating with vast masses of data. The essential component of the Hive is HiveQL, which is an SQL-like interface, widely used to query data stored in databases.
Hive has a benefit of disposing of rapid fast data reads and writes in the data warehouse along with manipulating massive datasets scattered across multiple locations. This is because of its unique SQL-like features. Hive implements a pattern to the data that previously collected in the database. Users can utilize the command-line tool and a JDBC driver to connect with Hive.
Hive is a much-demanded profession to learn to put forward in the Big Data Hadoop environment. Nowadays, most businesses are searching for professionals with expert skills to analyze and to query vast heaps of data. Therefore, learning Hive will pave your way to drive the highest salaries in one of the top organizations around the globe.