
What is MapReduce?
MapReduce is a framework from which we can address requests to process vast volumes of data, while correspondence; on massive bunches of stock hardware in a secure way.
MapReduce is a processing system and a business design for shared computing based on java. The MapReduce algorithm includes two major tasks:
- Map – it derives the group of data and transforms them into a different group of data, where unique components are separated down into multiple parts such as key or value pairs.
- Reduce – It reaps the output of a map as an input and connects those multiple data into a more inadequate set of data. As the course of the title MapReduce indicates, the reduce task is usually carried out only after the map task.
The primary benefit of MapReduce is that it is simple to compute data processing over various computing links. With the MapReduce design, the primitive data processing tasks are termed as mappers and reducers. Disintegrating a data processing request into mappers and reducers is occasionally not trivial. However, once we formulate a request in the MapReduce form, computing the request to operate over multiples of devices in a batch is solely a configuration switch. This capacity to be changed in size or scale is what has pulled many professionals to utilize the MapReduce model.
Best Big Data Hadoop Institute in Coimbatore is an institute that provides Big Data training in Coimbatore. It provides a certificate and degree level of education to those people who want to achieve their career objectives in the field of Big Data. Big Data Institute provides a certificate in Big Data and degree in Big Data at different locations across India. Big Data Institute provides a course for BCA, BBA, MCA and MBA. The programs offered by the institute are accredited by accreditation services. Many students enrol for BCA and BBA from Big Data institute in coimbatore.

MapReduce Algorithm
- Usually, the MapReduce model is based on assigning the task to the computer to where the data remains.
- MapReduce model accomplishes in three different phases, namely:
- Map phase
- Shuffle phase
- Reduce phase
Map phase − The map or mapper’s task is to perform the actions on the input data. Commonly, the input data will be in file format or directory and will be saved in the Hadoop file system (HDFS). The input file is moved to the mapper function in order. The mapper then starts processing the data and produces various small pieces of data.
Reduce Phase − This phase is the magnificent blend of the Shuffle phase and the Reduce phase. The Reducer’s task is to operate the data that arises from the mapper. Following the processing task, it creates a new collection of output, and the result is then stored in the HDFS.
- During the operation of MapReduce, Hadoop transfers the Map and Reduce jobs to the relevant servers inside the cluster.
- The model handles all the aspects of data-passing like assigning tasks, testing task performance, and designating data throughout the cluster within the nodes.
- The computing tasks mostly take place on nodes with data on local disks that lowers the network traffic.
- Right after the completion of the assigned chores, the cluster receives and humiliates the data to form a relevant result, and throws it back to the Hadoop server.
Sparkdatabox is one of the best Free online training course with certification They offer Oracle Database, Java, Apache Tomcat, SQL and other courses.
The working mechanism of MapReduce
There are two types of objects that manage the entire execution process of Map and Reduce tasks. The two objects are:
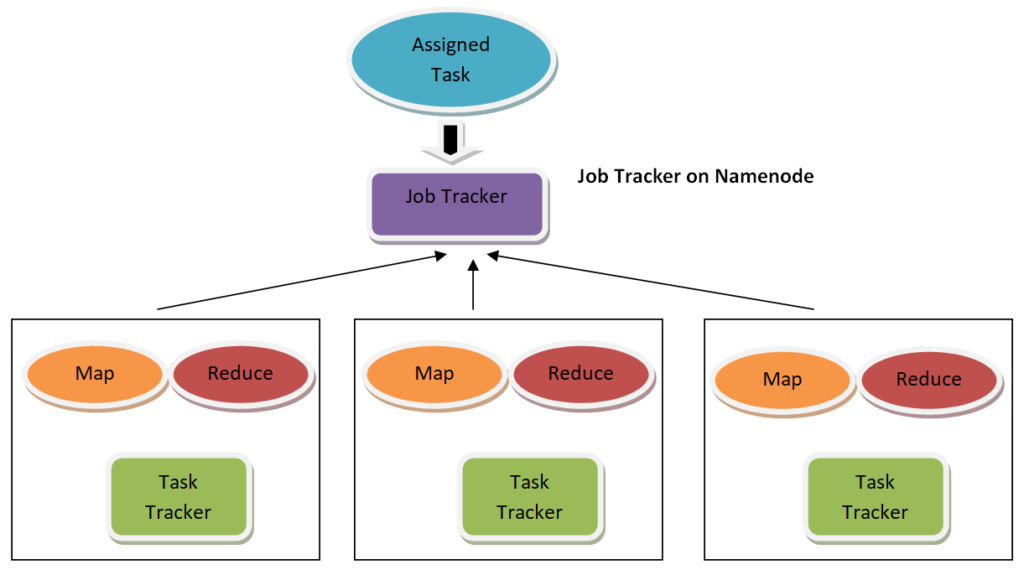
- Jobtracker: It is the primary object that masters the whole process of the assigned task
- Multiple Task Trackers: It plays the role of Slave, where each of the trackers performs the task
It locates two different nodes for each task provided for execution.
- Jobtracker that dwells on Namenode
- Multiple task trackers that dwell on Datanode
The processes described in the flow diagram are as follows along with the flow diagram:
- A task gets split into multiple tasks, which are later operated over multiple data nodes within the cluster.
- The job tracker has to organize the action by listing tasks to operate on multiple data nodes.
- The accomplishment of a specific task has to be observed by a task tracker that dwells on every data node, performing its role of the responsibility.
- The task tracker has to post the current report to the task tracker.
- Besides, the task tracker regularly addresses the ‘heartbeat’ sign to the Jobtracker to inform about the current status of the operation.
- Therefore task tracker grasps the course of the overall process flow of each assignment. In the case of task breakdown, the task tracker can reorganize it on a distinct task tracker.
Input and Output Format
The MapReduce paradigm works towards (key, value) pairs. The model observes the input task as a collection of (key, value) pairs and presents a collection of (key, value) pairs as the output task, usually of different varieties.
The model must complete the serialization of key and value pairs in order to perform the Writable interface.
Moreover, the key classes should perform the Writable-Comparable interface to promote listing by the paradigm.
A sample of Input and Output of a MapReduce task are as follows:
Input -> map (k1, v1) →Output list (K2, v2)
Input -> reduce (K2, list (v2) →Output list (k3, v3)
The MapReduce terms and roles
- NamedNode − Controls the Hadoop Distributed File System (HDFS)
- DataNode − This is the Node where data is conferred in advance before any processing occurs
- MasterNode − Here where JobTracker operates and receives job applications from clients
- SlaveNode − Here is where Map and Reduce application works
- JobTracker − It lists the tasks and tracks the submitted tasks over Task tracker
- Task Tracker − Tracks the task and addresses the status to JobTracker
- Task − It is an accomplishment of a Mapper or a Reducer on the part of data
Advantages of MapReduce
The two most prominent benefits of MapReduce are:
1. Parallel Processing
In MapReduce, the tasks are divided amongst multiple nodes, and each node operates with a portion of the task concurrently. Therefore, MapReduce is based on the Divide and Capture model, which supports us to process the data utilizing distinct machines. As multiple devices process the data rather than an individual device in parallel, the time needed to process the data is gradually reduced to a greater extent.
2. Data Locality
Rather than migrating data to the processing system, we are driving the processing system to the data in the MapReduce paradigm. In the conventional method, we used to carry data to the processing system and process it. However, as the data developed and slowly changed into a huge volume, carrying this large volume of data to the processing system faces, some problems are as follows:
- Driving a huge volume of data to the processing system is expensive, and it worsens the network function and effective performance.
- Processing demands more time as the data is processed by an individual system, which delays the traffic flow.
- The master node will get heavily loaded and will get failed to process the task.
- MapReduce enables us to defeat the listed problems by carrying the processing system to the data. Therefore, the data is shared between multiple nodes where each node processes the portion of the data dwelling on it. This enables us to possess the following benefits:
- It is highly cost-effective to drive the processing system to the data.
- The processing rate is decreased as every node is operated through parallel processing of data.
- Each node becomes a member of the data to process, and hence, there is no possibility of a node becoming overloaded.